マルチテナント構成の DB データ分離についての選択肢
今までなんとなくだったマルチテナント構成におけるデータベースのデータ分離についてどのような選択肢があるのかについて、改めて調査してみました。 本記事では、考えられる選択肢とそれぞれのメリット・デメリットを整理し、意思決定の参考になるようまとめられればと思います。
マルチテナントとは?
シングルテナントとの違い
シングルテナントは、1 つの顧客(テナント)に対して独立したシステム環境を提供する方式です。このため、データやシステムが完全に分離されており、高いセキュリティと柔軟なカスタマイズが可能ですが、インフラコストが高くなります。 シングルテナントの粒度として、アプリケーションサーバーが完全に独立しているものもあれば、DB サーバーのみが完全に独立しているものも様々です。
マルチテナントは、複数のテナントが同じシステム基盤やアプリケーションを共有する方式です。運用コストを削減し、システムを効率的に運用できますが、データの適切な分離が求められます。
シングルテナント vs. マルチテナント
| 観点 | シングルテナント | マルチテナント |
|---|---|---|
| コスト | 高い(各テナントごとにインフラを用意) | 低い(インフラを共有) |
| セキュリティ | 完全分離で高セキュリティ | 分離の実装が必要 |
| カスタマイズ性 | 柔軟なカスタマイズが可能 | 共有基盤のため制限あり |
| 運用管理 | 個別管理が必要で複雑 | 一元管理が可能で効率的 |
| スケーラビリティ | 個別スケールが必要 | リソースを効率的に共有可能 |
マルチテナントのデータ分離方法
マルチテナント構成におけるデータ分離方法は、大きく 3 つのアプローチに分類されます。
1. サイロモデル
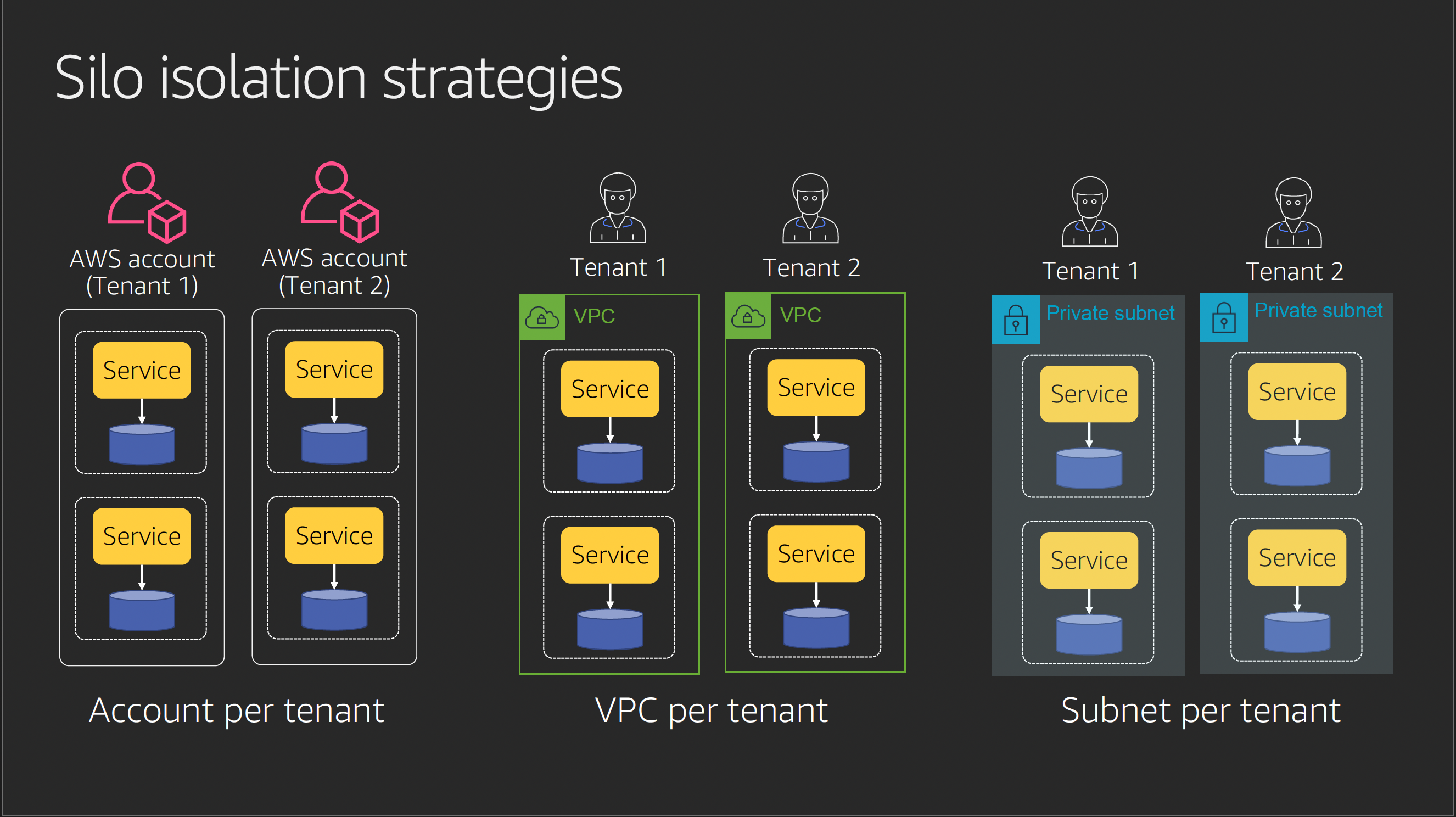 出展: AWS re:Invent 2019: SaaS tenant isolation patterns (ARC372-P)
出展: AWS re:Invent 2019: SaaS tenant isolation patterns (ARC372-P)
サイロモデルは、各テナントに対して完全に独立したインフラストラクチャとアプリケーションスタックを提供する方式です。これは最も高いレベルのデータ分離を実現し、セキュリティと独立性を重視する場合に適しています。いわゆる DB のシングルテナントのパターンです。
2. プールモデル
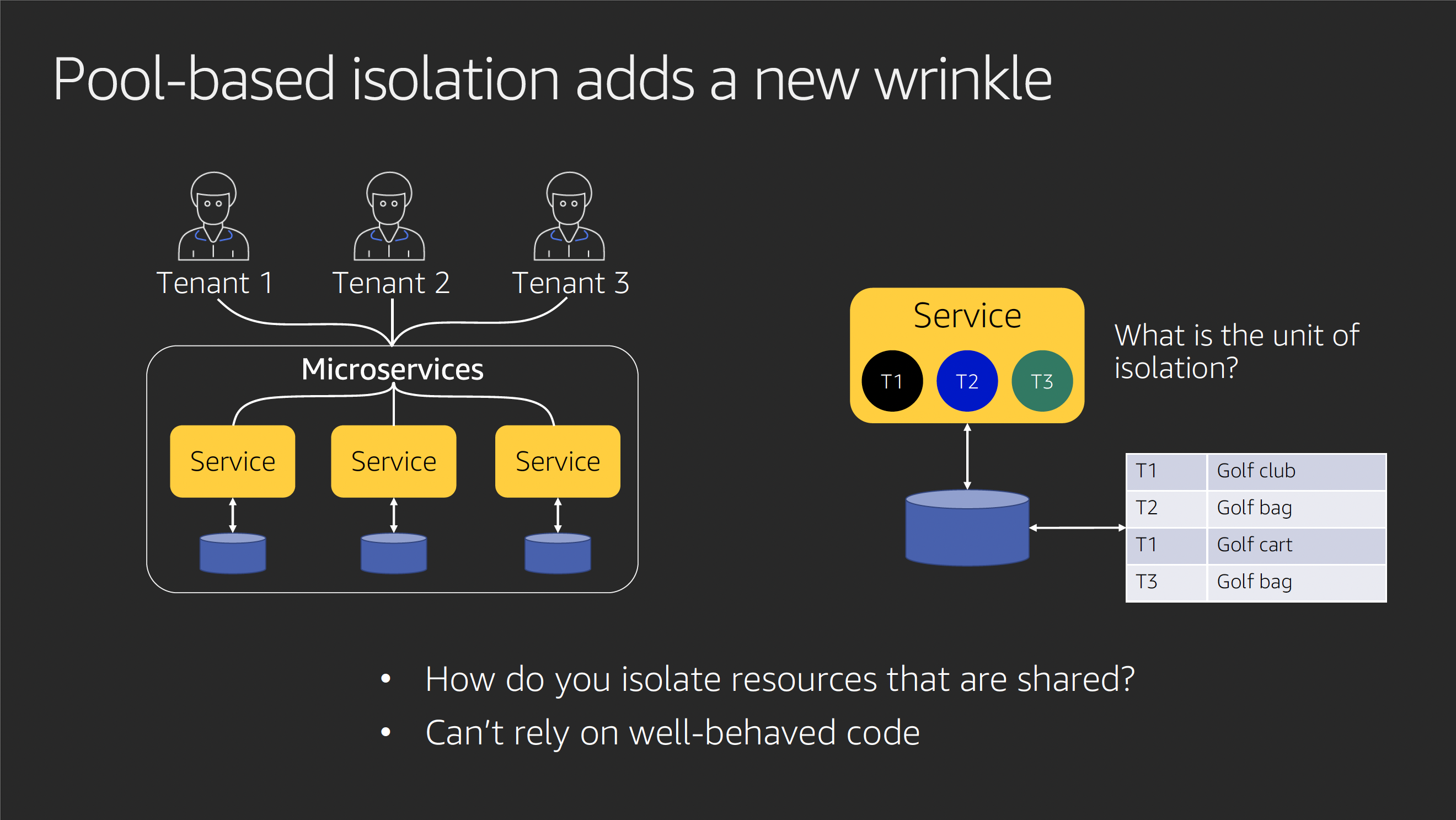 出展: AWS re:Invent 2019: SaaS tenant isolation patterns (ARC372-P)
出展: AWS re:Invent 2019: SaaS tenant isolation patterns (ARC372-P)
プールモデルは、複数のテナントが同じインフラストラクチャやアプリケーションリソース(DB、アプリケーションサーバー)を共有する方式です。 このモデルでは、データの論理的な分離を実装することで、各テナントのデータを保護します。分離のレベルは以下の 3 つに大きく分類されます:
a. スキーマレベルの分離
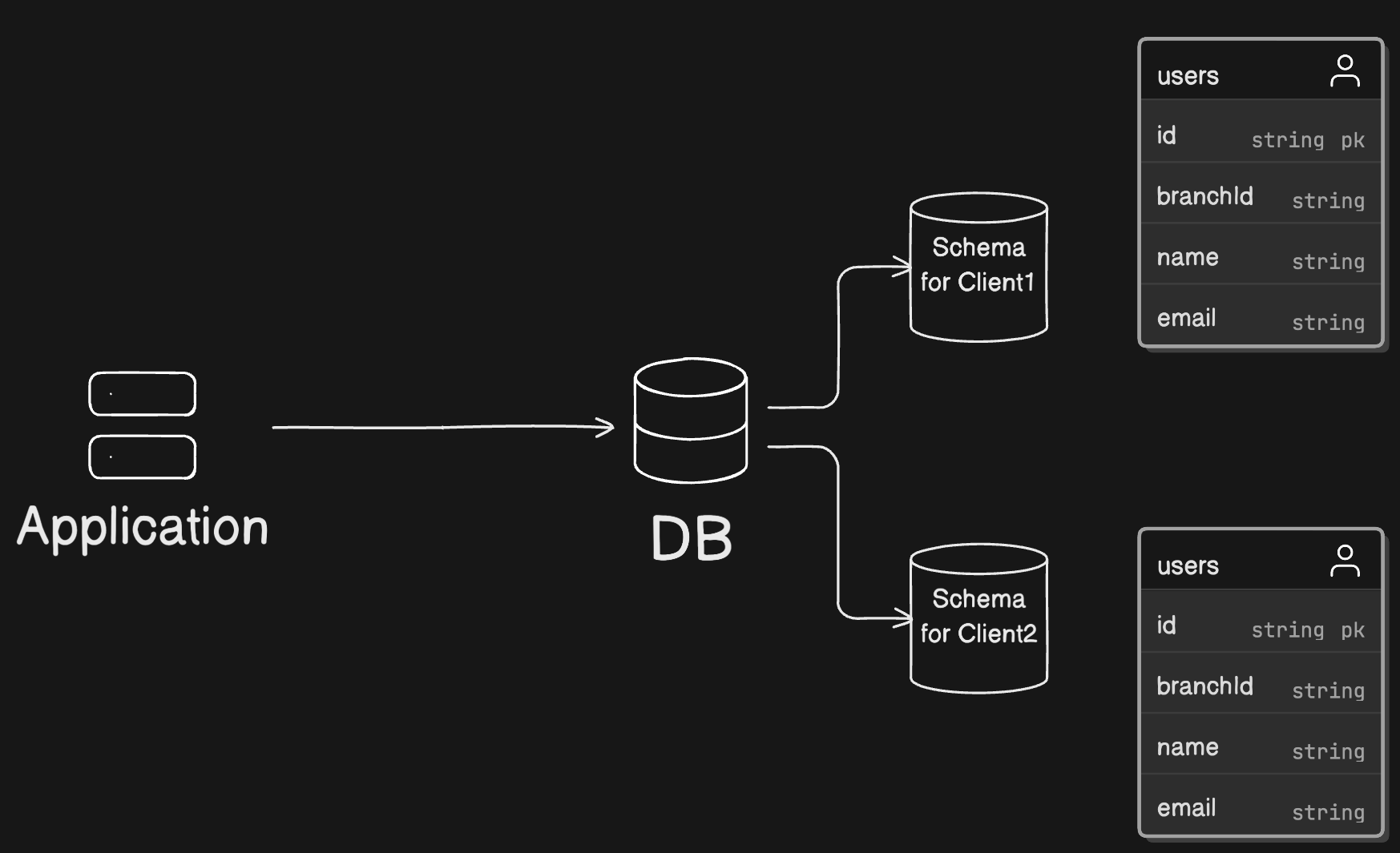
データベースのスキーマレベルで分離を行う方式です。各テナントに専用のスキーマを割り当て、論理的な分離を実現する方法です。 スキーマレベルの分離により、テナントごとのデータ構造のカスタマイズが容易になり、また他のテナントのデータへのアクセスを物理的に制限することができますが、アプリケーション側でテナントごとのデータを扱う必要があり、コードの複雑性が増してしまうのと、テナントが増えた時にそれぞれのスキーマに対して Migration を行う必要が出てきます。
b. テーブルレベルの分離
テーブルレベルの分離では、同じデータベース内で各テナントごとに専用のテーブルを用意する方式です。テーブル名にテナント ID を付与するなどして、テナントごとにデータを物理的に分離します。この方式は、テナントごとのデータ構造の独立性を保ちながら、データベースインスタンスを共有できるという利点があります。 ただし、スキーマレベルの分離と同様にコードの複雑性と Migration の難易度が増してしまうというデメリットがあります。
c. 行レベルの分離(Row Level Security: RLS)
行レベルの分離は、同じテーブル内で複数のテナントのデータを保持し、各行にテナント ID を持たせることで分離を実現する方式です。 PostgresSQL の場合、データベースの行レベルセキュリティ(Row Level Security: RLS)機能を活用することで、テナントごとのアクセス制御を実装できます。この方式は、データベースリソースを最も効率的に利用できる一方で、テナント間のデータ分離を確実に実装する必要があります。
3. ブリッジモデル
ブリッジモデルは、サイロモデルとプールモデルの利点を組み合わせたハイブリッドなアプローチです。例えば、重要なデータや機密性の高い機能はサイロモデルで完全に分離し、共通の機能やリソースはプールモデルで共有するといった使い分けが可能です。これにより、セキュリティと効率性のバランスを取ることができます。
プールモデルの実現方法と利用事例
Row Level Security(RLS)
Row Level Security (RLS) は、データベースレベルでテナント間のデータアクセスを制御する仕組みです。各データ行に対して、どのユーザーやロールがアクセスできるかをきめ細かく設定できます。PostgreSQL などのデータベースでネイティブにサポートされており、アプリケーションレベルでの実装を必要とせず、セキュアなマルチテナント環境を実現できます。
終わりに
マルチテナントに関して調べた結果、いくつかの手段があるものの状況によって取れる手段というのが自ずと決まってきそうだというのが、感想です。
例えば、エンタープライズ向けのシステムでセキュリティ要件が厳しいような企業が利用する場合や、セキュリティ的に外部に漏れたら困るようなデータを保管するサービス特性である場合は、自ずとサイロモデルを採用することになると思います。 一方で、サービスの特性としてセキュリティ要件が緩い場合は、プールモデルを採用して運用していくことになります。(あえてサイロモデルを採用する必要性がなければ)
また、サービスの成長とともにテナント数が増えてくると、プールモデルでの管理でも良かったが、データの分離を厳しくも求められるようになる場合、ハイブリッドであるブリッジモデルを採用するか、サイロモデルに移行するなどの判断が必要になってくるなどが考えられます。
このように、サービスの特性、利用企業のセキュリティ要件、ビジネスの成長によって、どのようなマルチテナントの実現方法を採用するかが変わってくるため、どこまでを許容できるかをビジネス観点で考えられることが重要だと理解しました。 エンジニアとしては、現状のビジネスの要件を見据えた上で、将来的な拡張性を考慮してアーキテクチャを設計することが重要だと改めて理解しました。
プールモデルで最も一般的な実装方法は PostgresSQL の RLS の利用です。ただしこの機能は MySQL ではサポートされていないため、MySQL を利用する場合はスキーマレベルの分離を行うか、RLS の代替手段として View を利用することになるようです。 自分が調べた限りだと、あまり採用事例が多くないようなので他の手段もあればそれも検討してみるのも良いかもしれません。
🔗 参考資料
-
SaaS アーキテクチャ 入門編
マルチテナント SaaS とは【AWS BlackBelt】 全体のイメージを持つのに役立ちました。マルチテナント SaaS アーキテクチャの構築の訳者の方の発表動画です。 -
マルチテナントの実現における技術選定の審美眼と DB 設計 PostgreSQL を利用した RLS の全容と、具体的な利用方法についての解説がわかりやすかったのでおすすめです。
-
PostgreSQL 16.4 文書 - CREATE POLICY 具体的にどのように RLS を実現するのかについての公式のドキュメント